
ظهور چیپلت ها • مقالات • دانش دانش ، کیت های طراحی تراشه برای ادغام ناهمگن 3D IC | نرم افزار زیمنس
استفاده از کیت های طراحی چیپلت برای کمک به هموار کردن راه برای ادغام ناهمگن 3D IC
چند سال بعد ، اولین پردازنده ها به ویژه با ویژه امروز اینتل 4004 ظاهر شدند. سپس پردازنده ها پیچیده تر شدند.
ظهور چیپلت ها
پس از بحث در JZDS و اختلاف نظر ، من به خودم گفتم که نوشتن مقاله ای در مورد چیپلت ها برای بیشترین تعداد مفید خواهد بود. و بر خلاف آنچه می تواند برای JZD ها اتفاق بیفتد ، یک آهنگ مکتوب را حفظ می کند
به جای نوشتن بلیط بسیار طولانی ، من قالب مقاله را ترجیح می دهم تا کمی بیشتر به جزئیات برسم. من امیدوارم که بتوانم به شما یاد بدهم که چیپلت ها چیست ، چرا این فناوری ایجاد شده است و چرا در سالهای آینده توسعه خواهد یافت.
- مقدمه
- چیپلت ، Quésaco ?
- جنبه های اقتصادی چیپلت
- دو مثال: AMD و اینتل (Altera)
مقدمه
در این مقاله در مورد مفاهیم رایانه ، الکترونیکی و معماری رایانه ها صحبت می شود که می توانند به اندازه کافی برای خوانندگان خاص پیشرفت کنند. من در این مقدمه کمی محبوبیت به شما ارائه می دهم تا کمی بهتر از آنچه در مورد آن صحبت می کنیم درک کنید.
برای پاکسازی ها ، میانبرها ساخته می شوند ، این محبوبیت ممکن است بتواند اطلاعاتی نامناسب داوطلبانه برای تسهیل درک داشته باشد.
چیپلت ، Quésaco ?
بیایید با دشوارترین شروع کنیم ، تعریف کنید که یک چیپلت چیست !
در واقع اصطلاح چیپلت در دهه 1970 ظاهر شد اما استفاده از آن عمدتاً در سالهای اخیر از بین رفته است ، برای کسانی که به پردازنده های پیچیده یا تراشه های الکترونیکی مانند FPGA علاقه مند هستند (تراشه هایی که درهای منطقی داخلی آنها می تواند دوباره برنامه ریزی شود). برای دیگران ، در پایین اتاق ، شاید شما هرگز از این اصطلاح نشنیده باشید ، ما آن را اصلاح خواهیم کرد !
بیایید به مبنای آنچه یک تراشه الکترونیکی است برگردیم: یک قطعه سیلیکون حکاکی شده (ترانزیستورهای معروف) که در یک مورد محصور شده است. با اجزای عبور ، نخ های کوچک طلا یا نقره پاهای مؤلفه را به قطعه سیلیکون وصل می کنند. در آغاز ، تراشه ها از ترانزیستورهای حک شده با وضوح نسبتاً درشت (در مقایسه با امروز) ساخته شده اند و توابع کاملاً اساسی بودند: درهای منطقی ، آمپلی فایرهای عملیاتی و غیره. با این حال ، این پیشرفت عظیم از نظر کوچک سازی بود !
در آن زمان اجزای دارای پاهای عبور بودند و لازم است تراشه سیلیکون را به این پاها وصل کنید. این گیاه با فرزندان نازک نقره یا طلایی ساخته شده است که بین تراشه و پاهای داخل کیس جوش داده می شود.

چند سال بعد ، اولین پردازنده ها به ویژه با ویژه امروز اینتل 4004 ظاهر شدند. سپس پردازنده ها پیچیده تر شدند.
از دهه 1970 ، IBM اجزای MCM را توسعه داد (چند کلیسا) شامل چندین تراشه سیلیکون در یک مورد واحد. اما این فناوری عمدتاً در اواخر دهه 90 توسعه خواهد یافت. ما می توانیم توجه داشته باشیم که پنتیوم طرفدار اینتل در سال 1995 منتشر شد. این پردازنده شامل دو تراشه سیلیکونی است: یکی برای پردازنده به طور دقیق و دیگری برای حافظه حافظه پنهان L2 (حافظه بافر بین پردازنده و رم ، بسیار سریعتر اما بسیار گرانتر است زیرا حکاکی شده با پردازنده).

همانطور که در عکس می بینیم ، دو تراشه تقریباً به یک اندازه یکسان هستند و اینتل چندین اندازه حافظه پنهان L2 را ارائه داده است. مزیت جدا کردن پردازنده حافظه حافظه پنهان این بود که بتوانید مقیاس را در تراشه پردازنده ذخیره کنید در حالی که با قرار دادن یک تراشه با اندازه متفاوت در مورد ، اندازه های مختلف حافظه حافظه پنهان را ارائه می دهید.
این نوع مؤلفه نسبتاً توسعه نیافته باقی مانده است ، حتی اگر IBM به توسعه اجزای MCM ادامه دهد. توجه داشته باشید Power5 IBM منتشر شده در سال 2004 که چهار پردازنده را با یک تراشه حافظه حافظه پنهان L3 مشاهده می کند. اتصال کک در داخل کیس انجام می شود.

امروزه این فناوری تکامل یافته و تراشه های MCM در محصولات مصرفی با پردازنده های AMD وجود دارند. در اینجا ما می توانیم یک پردازنده EPYC 7702 (منتشر شده در آگوست 2019) متشکل از 9 تراشه سیلیکون به هم پیوسته را مشاهده کنیم: 8 تراشه حاوی هسته و حافظه حافظه نهان و یک تراشه مرکزی که 8 مورد دیگر را به هم وصل می کند و DDR را مدیریت می کند و همچنین سیگنال های ورودی D/ ورودی/ سیگنال ها خروج (SATA ، PCI Express ، USB و غیره.).

اما به من بگویید جامی ، چیپلت چیست ?
آه بله ، من کمی مشتق شدم
در واقع یک چیپلت یکی از تراشه های سیلیکونی است که در یک MCM موجود است. یک چیپلت ساخته شده است تا با سایر چیپلت ها به هم پیوسته باشد. بله نسبتاً ساده است اما برای درک باید عکسهای خوبی را نشان دهید
با این وجود ، کمی دقیق تر در مورد معنای چیپلت ها ، این ایده لزوماً این نیست که چندین تراشه مختلف را به هم وصل کنیم. همچنین مفهومی از تراشه عمومی وجود دارد که قابل استفاده مجدد است و به یک مرجع پردازنده خاص اختصاص نمی یابد.
جنبه های اقتصادی چیپلت
پس از این مقدمه در حالی که تصویر ، اکنون به ما درک کنید که چرا چیپلت ها در آینده توسعه می یابند. برای انجام این کار ، لازم است به فرآیند تولید کک های الکترونیکی برگردید.
به راحتی در صندلی صندلی بنشینید زیرا سفر از ساحل شنی طولانی خواهد بود
نه ، صبر کن !
ما بخش کاملی از تولید سیلیکون را می گذرانیم. آنچه ما را مورد علاقه ما خواهد بود توزیع کک ها است (مردن) روی کیک سیلیکون (ویفر) و به ویژه تکامل عملکرد با افزایش ظرافت حکاکی.
اما قبل از این جنبه از عملکرد ، باید در مورد حداکثر اندازه فیزیکی یک قالب صحبت کنیم. در واقع ، روی یک پنکیک سیلیکونی همان طراحی یک تراشه چندین بار تکرار می شود (ده ها یا حتی صد بار). برداشت این طرح به صورت نوری از طریق نور ماوراء بنفش انجام می شود. با این حال مجموعه ای کامل از لنزها و مکانیسم های نوری وجود دارد که مانع از حکاکی یک قالب در کل کیک سیلیکون می شود.
هرچه کک ها را بیشتر پیچیده کنیم ، بیشتر می خواهیم ترانزیستورها را قرار دهیم ، بنابراین باید اندازه تراشه را افزایش دهیم ، یا ظرافت حکاکی را افزایش دهیم تا ترانزیستورهای بیشتری را در همان سطح قرار دهیم. اما محدودیت ها و محدودیت های دیگری نیز وجود دارد.
به همین دلیل است که اصل چیپلت برای دور زدن این حد جالب است: از چندین تراشه سیلیکوم کوچک که به هم متصل هستند استفاده کنید تا یک تراشه پیچیده تر را بسازند اما حکاکی به روشی یکپارچه غیرممکن است.
اکنون به بازده بازگشت (بازده به انگلیسی). اول ، ویفرها به شکل گرد هستند و ما می خواهیم آن را با تراشه های مستطیل حک کنیم. از کل سیلیکون استفاده نمی شود. اما هرچه در لبه ها کوچکتر باشد و بیشتر می توانیم بمیرد. این همان اصولی است که در یک بازی ویدیویی مبهم است: هرچه پیکسل هایی برای شکل دادن به شکل گرد استفاده می شوند کوچک هستند و کمتر متوجه می شویم.
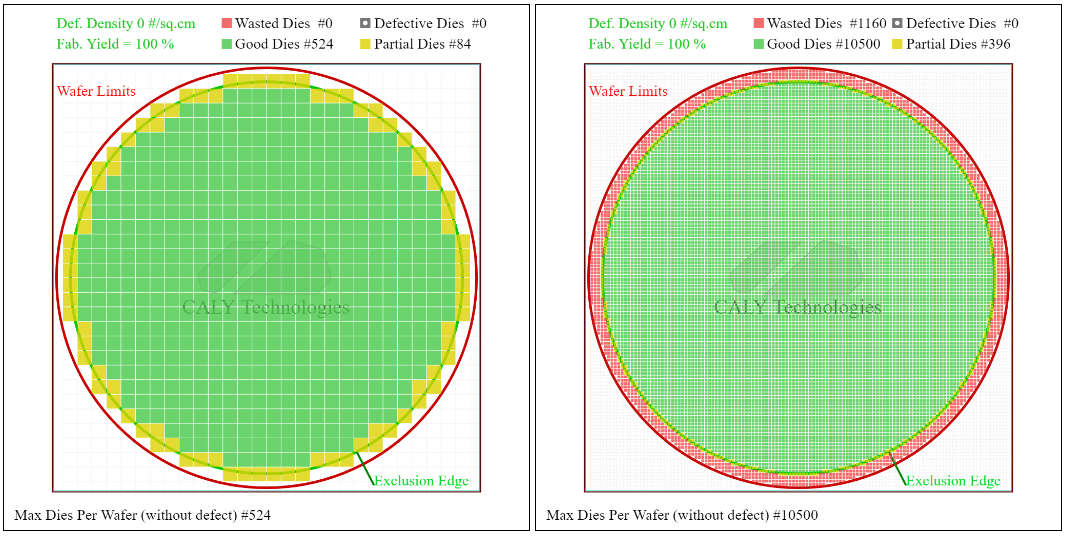
در مثال بالا ، اگر گزارش های جزئی در مورد تعداد کل مرگ (خوب و تعصب) را گزارش کنیم ، نسبت 13 به دست می آوریم.8 ٪ در مورد مرگ 5 × 5 میلی متر و 3.6 ٪ در مورد 1 × 1 میلی متر می میرد. هرچه قالب کوچکتر باشد ، می میرند در لبه ها می توانند بر روی لبه ها داشته باشند ، که باعث افزایش عملکرد می شود.
همچنین می توانید در مرکز ویفر یک مخلوط بزرگ قالب بسازید و از مین های کوچکتر در لبه ها برای بهینه سازی عملکرد به دلیل عدم استفاده استفاده کنید.
به جمی بگویید ، چرا ما از ویفرهای گرد برای تهیه کک های مستطیل استفاده می کنیم ?
خوب ، این به دلیل روش ساخت سیلیکون به نام فرآیند Czochralski است که به شکل سیلندرها سیلیکون می دهد ، به برش های بسیار ریز برش داده می شود تا به آنها بدهد ویفرها.
دوم ، عملکرد تحت تأثیر نقص هایی است که ممکن است در ویفر ظاهر شود. می توانید به دانه های گرد و غبار که روی ویفر می افتند فکر کنید.
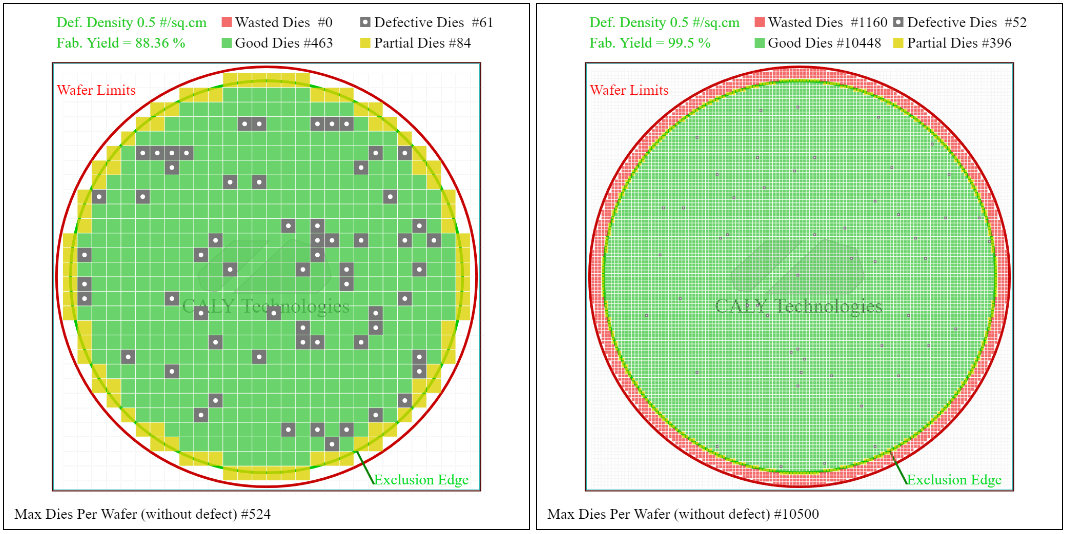
من با اضافه کردن چگالی گسل 0 مثال قبلی را از سر گرفتم.5 در هر سانتی متر مربع. اکنون مقایسه کنید تولید که مربوط به نسبت بین تعداد مردن عملکردی و تعداد کل محصولات تولید شده است. در مورد مرگ 5 × 5 میلی متر ، عملکرد 88 است.4 ٪ در حالی که 1 mm 1 میلی متر می میرد ، عملکرد 99 است.5 ٪.
بنابراین برای بهینه سازی تولید کک های الکترونیکی به طور دو برابر جالب است. با این وجود ، برش یک تراشه پیچیده به چندین تراشه کوچکتر نیاز به برقراری ارتباط با این تراشه های مختلف بین آنها دارد ، بنابراین باید عناصر ارتباطی را اضافه کنیم که فضای اضافی را به خود اختصاص داده و از انرژی اضافی استفاده می کنند.
علاوه بر این ، استفاده از چیپلت ها می تواند با توجه به توابع امکان تعدیل هزینه های تراشه نهایی با عملکرد ، از مرگ و میر مختلف حکاکی استفاده کند.
سرانجام ، یکی دیگر از جنبه های اقتصادی برای دیدن ، پیچیدگی توسعه ویژگی های جدید است. این تمایل به داشتن شرکت های تخصصی (یا حداقل در شروع کار) دارد که بلوک های مالکیت معنوی (توابع) آماده استفاده را ارائه می دهند. به عنوان مثال ، یک تولید کننده پردازنده قادر خواهد بود ضمن خرید Dies for Tables مانند PCI Express ، USB یا DDR ، بر توسعه خود پردازنده تمرکز کند.
برای تسهیل قابلیت تعامل چیپلت های حاصل از تولید کنندگان مختلف ، بازیکنان اصلی مانند Intel ، AMD ، ARM ، Qualcomm ، Samsung یا TSMC یک استاندارد ارتباطی بین تراپت ها ، UCIE ایجاد کرده اند (Express interconnect Chiplet جهانی).
دو مثال: AMD و اینتل (Altera)
AMD Epyc
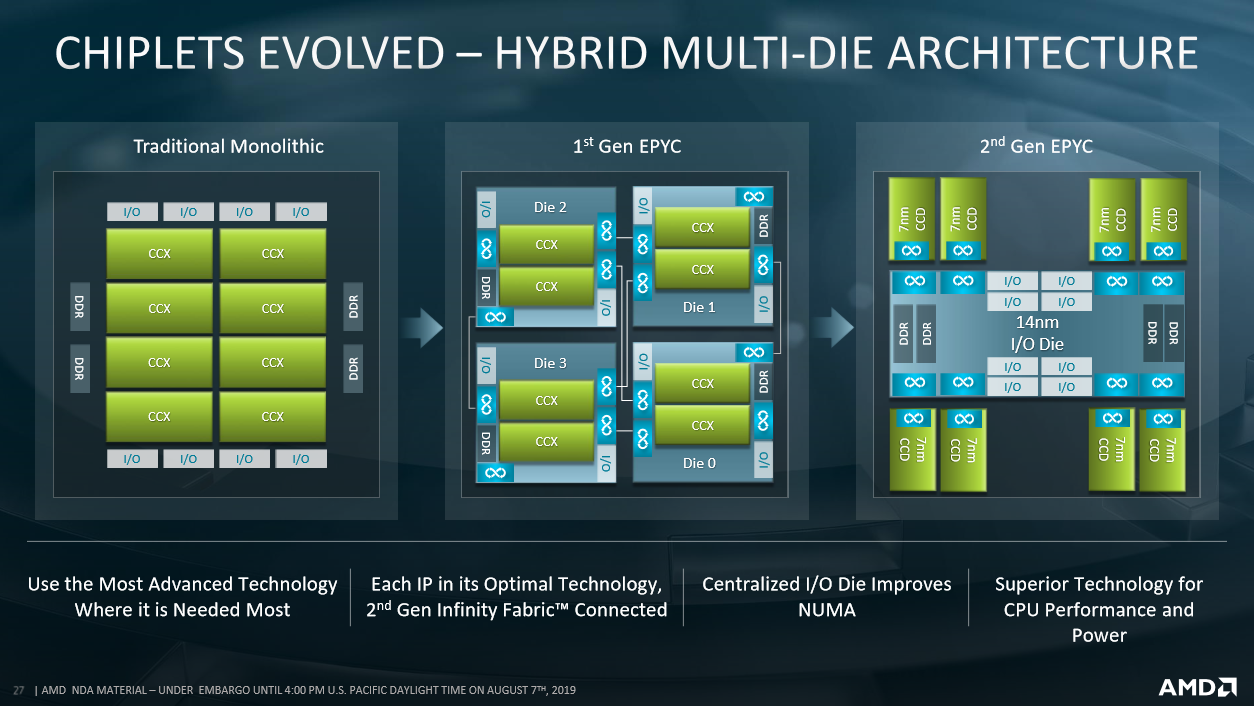
امروزه بیشتر و بیشتر پردازنده ها از این تکنیک چیپلت استفاده می کنند. AMD از اولین نسل پردازنده های EPYC از چیپلت استفاده می کند ، جایی که قلب های مختلف با هم در ارتباط هستندپارچه بینهایت.
نسل اول پردازنده های EPYC مجموعه ای از مرگ را دیدند که می تواند با پردازنده های کامل با هم در ارتباط باشدپارچه بینهایت برای تشکیل پردازنده نهایی. بنابراین چیپلت ها نوعی پردازنده خودمختار کوچک بودند: هرکدام از آنها ورودی ها/خروجی های خود را مدیریت می کردند و کنترلر DDR خود را داشتند.
این می میرند ، یا به اصطلاح چیپلت ها دو دارند مجموعه محاسبات هسته (CCX ، مجموعه ای از چهار هسته با حافظه حافظه نهان) و همچنین یک کنترلر DDR ، ورودی ها/خروجی ها را مدیریت می کند (به عنوان مثال PCI Express) و ماژول های ارتباطی برایپارچه بینهایت.
ظرافت های کوچک ، همیشه چهار چیپلت در نسل اول EPYC وجود دارد. برای تغییر تعداد قلب ها ، AMD قلب ها را در داخل CCX غیرفعال می کند. به عنوان مثال برای داشتن 24 هسته ، CCX فقط 3 هسته فعال دارد
بنابراین این نسل اول از اصل چیپلت ها به عنوان نوعی کپی/چسباندن درگذشت به جای ایجاد یک مرگ بزرگ یکپارچه استفاده کرد.
برای نسل دوم ، AMD کمی بیشتر مفهوم را تحت فشار قرار می دهد. در واقع ، CCX ها اکنون مستقل هستند ، به صورت جفت در یک گروه محاسبات اصلی می میرند (CCD) متصل توسط پارچه بینهایت به یک قالب مدیریت DDR و ورودی ها/خروجی ها گفته می شود من/ای می میرند (ید).
AMD به طور کامل از این جدایی افزایش یافته از توابع سوء استفاده می کند. در واقع CCD در 7 نانومتر حک شده است در حالی که IOD در 14 نانومتر حک شده است.
در زیر ارائه AMD خلاصه گذرگاه در چیپلت پردازنده های EPYC.
Intel FPGA (altera)
پردازنده های اینتل همیشه تراشه های یکپارچه هستند به جز چند استثنا که در ابتدای این مقاله می دیدیم. با این وجود در بخش Intel FPGA (تنظیم مجدد FPGA) از چیپلت ها برای آخرین نسل ، Agilex استفاده می کند.
این چیپلت ها عمدتاً مربوط به نوع تعصب مورد استفاده (پیوندهای سریع) هستند و نامیده می شوند کاشی. اگر اینتل دامنه های از پیش تعریف شده از این کاشی ها را ارائه دهد ، باید تراشه های سفارشی برای نیازهای خود داشته باشید.
کاشی ها با حداکثر سرعت گیرنده ها و پروتکل های پشتیبانی شده تقسیم می شوند (اترنت ، PCI اکسپرس و غیره.): 16 گرم برای P ، 28 گرم برای H ، 32G برای R و غیره.
اینتل همچنین برای آینده امکان اتصال چیپلت های سفارشی را فراهم می کند که عملکردهای اضافی را ارائه می دهد. در حال حاضر شرکت ها یک تراشه ADC/DAC (Jariett Technologies) و همچنین اتصال نوری دیگر (AYAR LABS) منتشر کرده اند.

سرانجام نباید باور کنیم که تراشه ها وابسته به یکپارچه مرده اند. آنها همیشه مزایایی دارند ، به ویژه از نظر ارتباطات داخلی و تأخیر ، که می تواند برای برخی از برنامه های کاربردی که به تراشه های بزرگ نیاز دارند بسیار مهم باشد.
این مورد Broadcom و تراشه های سوئیچ 400G آن است که انتخاب آنها توسط طراح در این فیلم توضیح داده شده است: https: // www.یوتیوب.com/ساعت?V = b-cogmbaug4
امیدوارم این مقاله به شما بیشتر باشد و به شما اجازه دهد کمی بیشتر در مورد ساخت تراشه های فعلی بدانید. من سعی کردم یک موضوع پیچیده را محبوب کنم ، همچنین امیدوارم که بتوانم بعد از اولین پاراگراف شما را حفظ کنم
در صورتی که نکات خاصی برای شما رمزنگاری باقی بماند ، از اظهار نظر دریغ نکنید ، من سعی می کنم جزئیات را ارائه دهم.
6 نظر

این پاسخ مفید بود
مقاله عالی ، متشکرم @ Zeql !
“مرا به گرگ ها پرتاب کن و من بسته را برمی گردانم.” – سنکا
این پاسخ مفید بود
من تعجب می کردم که چقدر ظهور چیپلت ها توانست تکامل خاصی را در سخت افزار در نظر بگیرد (همچنین درجه مصرف کننده این که سرور) در آینده ، یا حتی یک پارادایم تغییر در روشی که ما به طور کلی ماشین های بسیار و بهینه طراحی می کنیم.
برخی از سیستم های خوب یکپارچه (به ویژه در اپل) فقط بر اساس یک پردازنده “کلاسیک” بسیار کارآمد ، بلکه بر روی چندین تراشه کمکی تخصصی که CPU های عمومی را تخلیه می کنند. در یک سیستم محدود به عنوان یک تلفن هوشمند ، می توانیم تراشه های Transcoding H265 ، واحدهای محاسبه AI را پیدا کنیم (موتور عصبی اپل) و البته واحد گرافیکی کلاسیک.
بنابراین من نمودار AMD EPYC نسل 2 را می گیرم و نمی دانم که آیا چیپلت ها راهی ساده برای تولید تجاری و صنعتی قابل استفاده از واحدهای کامل هستند که چندین تراشه تخصصی را برای دستیابی به عملکرد بهینه در برخی کارها انجام می دهند. به عنوان مثال ، یک واحد می تواند CCD های کلاسیک ، بلکه DSP ، GPU ، Transco H265/AV1/VP9/… ، تراشه ای برای انجام AES و غیره را فراهم کند. و همه آن را از طریق تولید ید/Infinity وصل کنید. بنابراین هر تولید کننده ماشین آلات/سرور می تواند واحد نهایی آماده استفاده خود را با تهیه خود و بدون هزینه های صنعتی R&D/Faramineurous تشکیل دهد.
این مفهوم APU را به من یادآوری می کند ، اما من نمی دانم گزارش وجود دارد.

این پاسخ مفید بود
من تعجب می کردم که چقدر ظهور چیپلت ها توانست تکامل خاصی را در سخت افزار در نظر بگیرد (همچنین درجه مصرف کننده این که سرور) در آینده ، یا حتی یک پارادایم تغییر در روشی که ما به طور کلی ماشین های بسیار و بهینه طراحی می کنیم.
برخی از سیستم های خوب یکپارچه (به ویژه در اپل) فقط بر اساس یک پردازنده “کلاسیک” بسیار کارآمد ، بلکه بر روی چندین تراشه کمکی تخصصی که CPU های عمومی را تخلیه می کنند. در یک سیستم محدود به عنوان یک تلفن هوشمند ، می توانیم تراشه های Transcoding H265 ، واحدهای محاسبه AI را پیدا کنیم (موتور عصبی اپل) و البته واحد گرافیکی کلاسیک.
بنابراین من نمودار AMD EPYC نسل 2 را می گیرم و نمی دانم که آیا چیپلت ها راهی ساده برای تولید تجاری و صنعتی قابل استفاده از واحدهای کامل هستند که چندین تراشه تخصصی را برای دستیابی به عملکرد بهینه در برخی کارها انجام می دهند. به عنوان مثال ، یک واحد می تواند CCD های کلاسیک ، بلکه DSP ، GPU ، Transco H265/AV1/VP9/… ، تراشه ای برای انجام AES و غیره را فراهم کند. و همه آن را از طریق تولید ید/Infinity وصل کنید. بنابراین هر تولید کننده ماشین آلات/سرور می تواند واحد نهایی آماده استفاده خود را با تهیه خود و بدون هزینه های صنعتی R&D/Faramineurous تشکیل دهد.
این مفهوم APU را به من یادآوری می کند ، اما من نمی دانم گزارش وجود دارد.
بنابراین باید بدانید که یک تراشه اغلب با IP (مالکیت معنوی) انجام می شود: تابعی که در سطح “ترانزیستورها” کاملاً آماده است اما باید در طراحی آن ادغام شود.
یک مثال کلاسیک یک کنترلر DDR3 در میکروکنترلر در صفحه است. تولید کننده میکروکنترلر لزوماً به DDR3 تسلط ندارد و مهارت ندارد ، زمان (نه تمایل) برای ایجاد یک کنترلر DDR3. بنابراین او یک IP را از یک کنترلر خریداری می کند و او را در طراحی خود ادغام می کند.
شما باید موفق شوید تفاوت بین احتمال IP و یک چیپلت را ببینید. برای من چیپلت در آنجا آمده است که بیاید و یک یا چند ویژگی پیشرفته را بیاورد و قبلاً تست های حکاکی را پشت سر گذاشته است ، بنابراین یک گام اضافی در طراحی. اما مشکل آزمایش خاک کامل با تمام چیپلت ها وجود دارد. بنابراین ما نمی توانیم صدها تغییر مانند LEGO ایجاد کنیم. حداقل واقعیت اقتصادی را می طلبد.
اما بله ، برای یک حجم خاص می توانیم سوکت های à la carte ایجاد کنیم.
مزیت بزرگ در سمت تولید تراشه است: اگر می توان IP را برای ظرافت حکاکی های مختلف کاهش داد ، یک تراشه به نفع این است که همیشه در ظرافت اولیه خود حکاکی شود (اگر کافی باشد) وقتی تراشه سایر قسمت ها می تواند با حکاکی کوچکتر بهبود یابد.
این پاسخ مفید بود
علاوه بر این فکر کردم که از چیپلت ها می توان در یک طراحی مدولار استفاده کرد. شما با 4 تراشه طراحی می کنید ، کک هایی با گسل در طول تولید توزیع می شوند ، و آنهایی که 3 تراشه دارند که روی 4 کار می کنند ، دامنه زیر و کمی ارزان تر از آنهایی که 4 کار دارند ، خواهد بود.
که طراحی و صنعتی شدن را در رابطه با عملکرد معمولی ساده می کند.
عاشق نرم افزار رایگان و توزیع GNU/Linux Fedora. #Jesuisarius
این پاسخ مفید بود
با تشکر از شما برای این مقاله جالب مگا. من خیلی دوست دارم شما وقت زیادی را برای جزئیات هر نکته ای که شما در آموزش توضیح نمی دهید تا واقعاً چیزها را درک کنید اما به هر حال جالب است .
استفاده از کیت های طراحی چیپلت برای کمک به هموار کردن راه برای ادغام ناهمگن 3D IC

یک چیپلت یک قالب ASIC است که به طور خاص طراحی و بهینه شده برای کار در یک بسته در رابطه با سایر چیپلت ها. یکپارچه ناهمگن (HI) شامل چندین قالب یا تراشه های چندگانه در تراشه های سیستم در بسته بندی (SIP) است. این دستگاه های ارائه شده به مزایای قابل قبول ، شامل عملکرد ، قدرت ، منطقه ، هزینه و TTM.
تبادل طراحی چیپلت (CDX) شامل فروشندگان EDA ، چیپلت است
ارائه دهندگان/مونتاژ و یکپارچه سازنده SIP و یک کارگروه باز برای توصیه مدلهای استاندارد تراشه و گردش کار برای تسهیل اکوسیستم چیپلت است. این وبینار خلاصه ای از کیت های طراحی چیپلت (CDKs) برای کمک به استاندارد سازی 2 ارائه می دهد.5 و 3.طرح های D IC برای ایجاد یک اکوسیستم باز.
ساخت اکوسیستم برای موفقیت 2.ادغام مدل چیپلت 5D و 3D
مشابه یک فرآیند SOC ، شما به یک اکوسیستم برای تراشه ها نیاز دارید. کلیدی امکان پذیرش بازار عمومی و استقرار طرح های مبتنی بر تراشه را شامل می شود:
- فناوری: 2.5 D Interposition و 3D Propsed Die و Procese Movembly Die
- IP: مدل های تراشه استاندارد
- گردش کار: EDA Design جریان و قوانین PDK ، CDK ، DRM و مونتاژ
- مدل های تجاری: بازار چیپلت
تمرکز اولیه CDX 2 است.5D مدل های تراشه مبتنی بر مداخله با سه بعدی دنبال کنید. در مورد این تلاش ها در وبینار بیشتر بدانید.
تبادل طراحی چیپلت (CDX) شامل فروشندگان EDA ، ارائه دهندگان/مونتاژ تراشه ها و یکپارچه سازان SIP است و یک کارگروه باز برای توصیه مدلهای استاندارد تراشه و گردش کار برای تسهیل اکوسیستم چیپلت است. این وبینار خلاصه ای از کیت های طراحی چیپلت (CDKs) برای کمک به استاندارد سازی 2 ارائه می دهد.5 و 3.طرح های D IC برای ایجاد یک اکوسیستم باز.
ساخت اکوسیستم برای موفقیت 2.ادغام مدل چیپلت 5D و 3D
مشابه یک فرآیند SOC ، شما به یک اکوسیستم برای تراشه ها نیاز دارید. کلیدی امکان پذیرش بازار عمومی و استقرار طرح های مبتنی بر تراشه را شامل می شود:
- فناوری: 2.5 D Interposition و 3D Propsed Die و Procese Movembly Die
- IP: مدل های تراشه استاندارد
- گردش کار: EDA Design جریان و قوانین PDK ، CDK ، DRM و مونتاژ
- مدل های تجاری: بازار چیپلت
تمرکز اولیه CDX 2 است.5D مدل های تراشه مبتنی بر مداخله با سه بعدی دنبال کنید. در مورد این تلاش ها در وبینار بیشتر بدانید.
تصویر نشت شده ، طراحی بلندپروازانه ای از چیپلت را برای GPU AMD Radeon نشان می دهد
تصویر نشت شده ، طراحی بلندپروازانه ای از چیپلت را برای GPU AMD Radeon نشان می دهد
- توسط
- در اخبار
- در 16 اوت 2023

یک تصویر درز شده ظاهر شده است و یک طرح GPU را با چیپلت های Radeon نشان می دهد ، که ظاهراً از یک پروژه لغو شده از NAVI 4C Chip 4C. طراحی بین 13 تا 20 چیپلت مختلف در یک پردازنده گرافیکی واحد وجود دارد ، و این رویکرد جاه طلب AMD را شهادت می دهد. این طراحی چیپلت پیچیده تر با سیلیکون NAVI 31 در حال حاضر در Radeon RX 7900 XTX استفاده می شود. در حالی که تکرار قبلی GPU نسل اول در نظر گرفته شده بود ، از یک طراحی تراشه واقعی مانند پردازنده های اخیر Ryzen AMD استفاده نمی کرد. با این حال ، برداشت از NAVI 4C فاش شده ، پیشرفت قابل توجهی را نشان می دهد ، زیرا شامل چندین قطعه محاسبه و همچنین تراشه های I/O مجزا بر روی یک بستر واحد است. تصویر نشت شده 13 قطعه قطعه را نشان می دهد ، با امکان تراشه های کنترل کننده حافظه اضافی که روی تصویر نمایش داده نمی شود.
برای تأیید صحت تصویر ، یک حق ثبت اختراع مربوط به سال 2021 در مورد مفهوم مدولار در پردازنده های موازی برجسته شده است. الگوهای ثبت اختراع از نزدیک شبیه به طراحی نشان داده شده در تصویر درز شده است ، حتی نشان می دهد که احتمال بندهای بیشتر در طرف دیگر فنجان عرضی.
متأسفانه ، طراحی GPU ارائه شده در تصویر فاش شده لغو شده است. این با روابط اخیر موافق است که نشان می دهد لهجه AMD برای نسل بعدی GPU در تراشه های یکپارچه NAVI 43 و NAVI 44 خواهد بود که برای عموم مردم در نظر گرفته شده است ، نه در مورد اجزای بالا. با این حال ، گمانه زنی شده است که AMD تلاش های خود را برای توسعه یک پردازنده گرافیکی متشکل از چندین قطعه محاسبه برای بخش بالا از محدوده های بعدی کارتهای گرافیکی خود ، به طور بالقوه با rDNA 5 تغییر می دهد.
اگرچه تحقق چندین تراشه محاسبه برای گرافیک بازی پیچیده تر از محاسبات سنتی CPU است ، اما تصمیم AMD برای غلبه بر موانع طراحی اکنون و کار بر روی یک راه حل بهتر برای RDNA 5 به عنوان یک گام مثبت درک می شود. این برای AMD برای داشتن یک برنامه نجات ، مانند یک گره جدید برای نسخه بهبود یافته Navi 31 سودمند خواهد بود.